

AI Magic - Time to Disco! Diffusion-based Generative Art Models
Second Installment of the AI Generative Art series for aspiring digital artists & AI beginners, but there's something for everyone! Let's Dance !


PROMPT: “Musicians and artists wearing sequins, velvet clothes, tight jumpsuits, furs, fluid satin dresses dancing Disco at Studio 54 in late 70s New York City, disco balls, bar tables with champagne glasses | render in vintage photo 70s style” using Disco Diffusion v5.2
Welcome to the second installment of the AI Magic - Generative Art series on Snippets & Bits. If you’re a newcomer, I strongly encourage reading the first installment - which provides an AI primer for interested non-technical readers including artists, hobbyists and beginner-level AI practitioners and a step-by-step walkthrough to generate your own images utilizing the VQGAN+CLIP models in a few easy steps.

After dabbling with the VQGAN+CLIP models and exploring the vibrant underground community, I moved on to the latest and greatest image generation tech, AI Diffusion Models.

PROMPT: “Damp dark Underground subway station with walls covered in graffiti tatscru , train tracks disappear in distance, flickering broken lights and highly illuminated bitcoins radiating on the floor” - Disco Diffusion v5.2
AI Diffusion Models - Overview
A couple of foundational papers were released early/mid 2021 by OpenAI researchers Prafulla Dhariwal and Alex Nichol describing the Diffusion model architecture and approach.
Improved Denoising Diffusion Probabilistic Models PAPER
Diffusion Models Beat GANs on Image Synthesis PAPER
The basic concept in a nutshell… the researchers developed a method where a training image, for example an image of a dog, can be slowly fed noise incrementally over many steps (thousands). After enough iterations, you now have a traceable history (think animation frames in a video/animation) of a training image, the dog, going from complete coherence to complete noise.

IMAGE CREDIT: Improved Denoising Diffusion Probabilistic Models paper, Prafulla Dhariwal and Alex Nichol
Well, the conceptual breakthrough lies in reversing this process, by ‘de-noising’ images from random noise into something comprehensible. The researchers train AI models to ‘de-noise’ images and the model effectively learns methods to walk backwards and traverse those ‘animation frames’ paths from a noisy image space back to a coherent, comprehensible image space. This reverse traversal requires some guidance, and that’s where the AI magicians got creative, enter CLIP.
Disco Diffusion - AI Diffusion Image Generator
Disco Diffusion v5.2 Colab Notebook Cheatsheet Discord Server
Disco Diffusion is the name of the Google Colab Notebook that marries an AI Diffusion model to the popular CLIP AI model (we introduced CLIP in the previous AI magic post), where a simple text prompt can help guide the AI diffusion model down relevant paths towards a comprehensible and tailored image, providing a bridge between NLP (CLIP) and a denoising diffusion model.
Excerpt from the Disco Diffusion cheat sheet…. “CLIP is a tool for labeling images. CLIP uses its image identification skills to iteratively guide the diffusion denoising process toward an image that closely matches a text prompt. Diffusion is an iterative process. Each iteration, or step, CLIP will evaluate the existing image against the prompt, and provide a ‘direction’ to the diffusion process to properly denoise an image”.
In summary, CLIP is the final piece to the solution, providing the guiding hand that helps keep the denoiser ‘on task’ when building an image that aligns to the text prompt provided. Together, they make Disco Diffusion one of the most powerful and magical art & image generation tools available today !
Links to additional material located in Resources section at the end of the post.

PROMPT: “"An AI Diffusion model fights an AI GAN Model for generative art supremacy inside of a computer in the cloud | render in Unreal Engine | Greg Rutkowski James Gurney Artstation" - Disco Diffusion v5.2
AI MAGIC - Disco Diffusion v5.2 Quickstart
Disco Diffusion v5.2 Colab Notebook Cheatsheet Discord Server
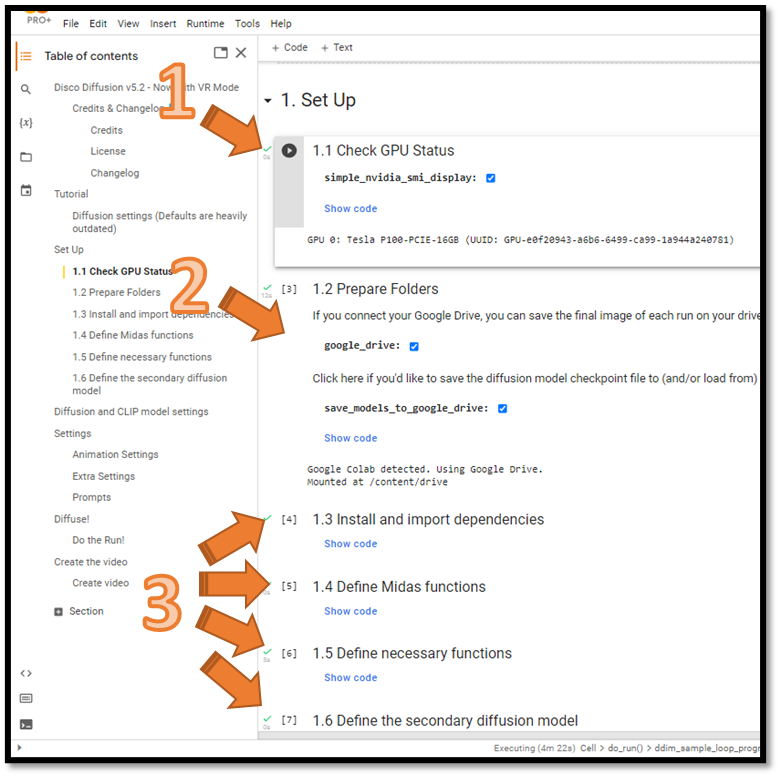
Quick walkthrough to start generating images. NOTE: Numbers (#) refer to orange numbers and arrows in the diagrams below.
#1 - Launch Notebook & Check GPU - Launch the Disco Diffusion Google Colab Notebook by pressing the play button under section 1.1 Check CPU Status. This will launch your Google Colab runtime (if its not running already). Note: the GPU being used for your notebook. If no GPU is found then you will not be able to run this notebook.
#2 - Prepare Folders & Google Drive - Do you have Google Drive with significant storage space available ? If so, you may want to check both boxes in section 1.2 Prepare Folders to utilize it for image storage and AI model storage. Press play button and move on. Note: leaving unchecked works just as well, just remember you will need to save your files locally before you close the browser / colab session.
#3 - Dependencies & Functions - Run the following sections, with their default values, in sequence 1.3, 1.4, 1.5, 1.6 (press their play buttons)
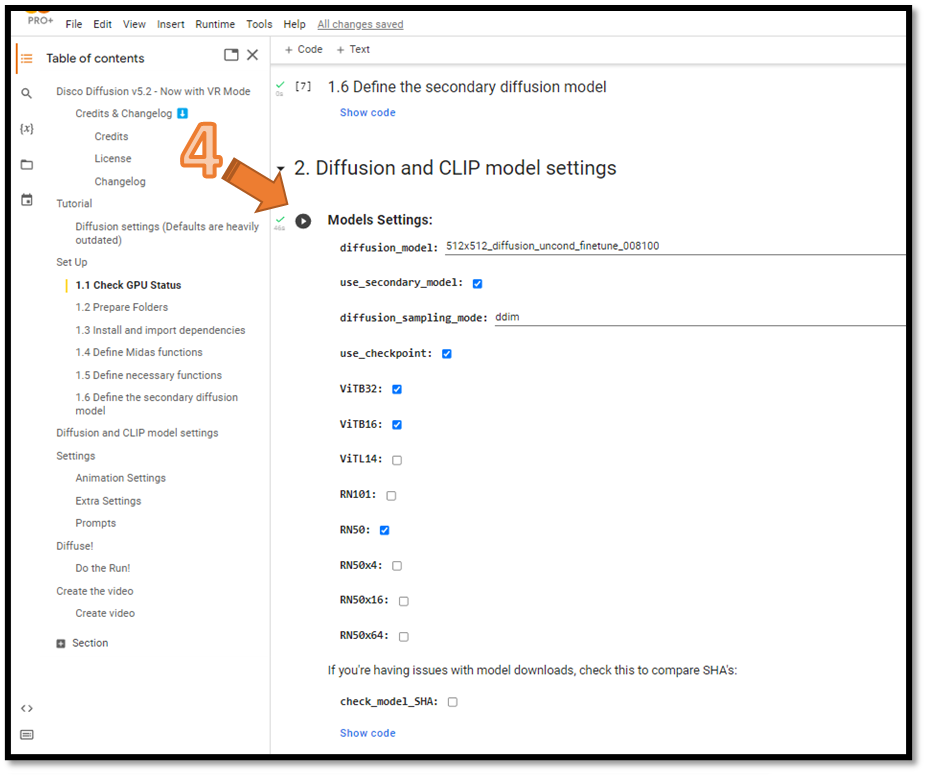
#4 - Diffusion & Clip Settings - Keep the defaults and press the play button
#5 - Basic Settings - Depending on your Google Colab Tier (free, Pro or Pro+), the following settings will impact your rendering abilities and times.
Steps - defines the number of images that get produced for one batch, I would recommend either 100 or 200 steps initially. Once you get the hang of it, then feel free to increase this value to 250 or 500 (even 1000, if you have the horsepower).
Image size - If you’re just starting off, I would recommend you change the width_height: setting to [256,256] or [512,512] .
Finalize Settings - Leave the remaining default values. Press the play button near the Basic Settings text (right below the 3. Settings title)
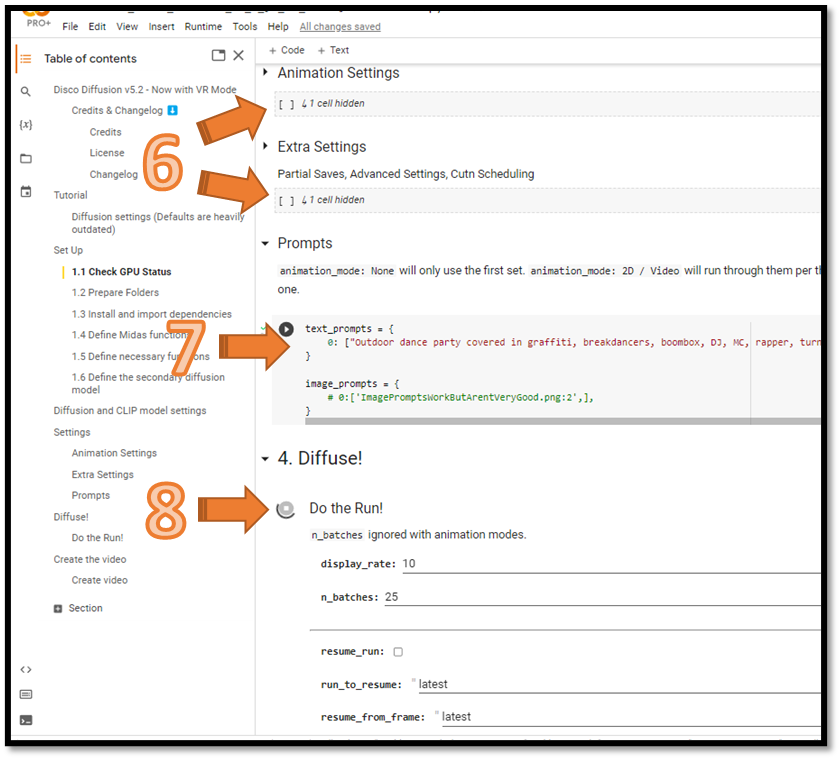
#6 - Animation & Extra Settings - Leave untouched, defaults are fine. You will need to adjust animation settings when you’re ready to render animations - but that’s a future post. Press play button for Animation Settings and Extra settings in sequence.
#7 - Prompts - the moment is finally here, this is where you define your text prompt to guide the AI to render a particular image. Be descriptive, there’s definitely an art to building your text prompts to get better results. See Resources & Links section at the end of the post for tips & tricks on constructing great text prompts. Once you update your text prompt, keep everything else with the default values and Press the play button to the left of the the text_prompts:
#8 - Diffuse ! - Get ready for some AI magic !! Press the play button to the left of the Do the Run! title directly under the 4. Diffuse title.
Here are several more sample images I was able to produce while experimenting.

PROMPT: “Kids living in a Minecraft world full of Creepers, zombies, farm animals and blue diamond swords | render in Unreal Engine” - Disco Diffusion v5.2

PROMPT: “An old elvish magician with mystical green robes teaches a classroom full of rowdy orc children students in a wood cabin schoolhouse early morning eerie fog, Greg Rutkowski James Gurney, Nicolas Pierquin artstation” - Disco Diffusion v5.2

PROMPT: “Woman in futuristic spacesuit staring illuminating discovery in a crystal ball | metallic yellow blue color style” - Disco Diffusion v4.1
Well folks, I’m out of time - hope you enjoyed the post. Here are some useful links and resources to learn more about AI Diffusion models and Disco Diffusion.
Resources & Links
Diffusion Disco 5.2 Colab Notebook & Cheatsheet & Discord Server
Text Prompt Tips & Tricks - Spanish version - English Version. Great prompt writing tips in the subreddit r/deepdream channel. Also look at CLIP Prompt Engineering for Generative Art
Relevant Twitter accounts (stolen from DD cheat sheet) somnai_dreams, gandamu_ml, zqevans, huemin_art, softologycomau , NerdyRodent, nonlethalcode, garlicml, pharmapsychotic, luciddreamnf1
AI - Yannic Kilcher YouTube Video on Diffusion Models Beat GANs on Image Synthesis paper.
AI - Yannic Kilcher YouTube Video on GLIDE Diffusion Model based Image Enhancer
AI - Google AI Blog - High Fidelity Image Generation Using Diffusion Models Super-Resolution via Repeated Refinements (SR3) and Cascaded Diffusion Models (CDM)